Hello @mecsbecs
thanks for the feedback,
I’ll do well to resubmit with the required details
In regards to members of the committee not being able to access (verify) recordings of other users,
- currently there’s no feature that let’s one user see the recordings of another.
- task errors occur when a user is yet to complete current task, gpt doesn’t create a new task until the existing task is complete
- when the platform requires that, we’ll make sure the users consent is gotten.
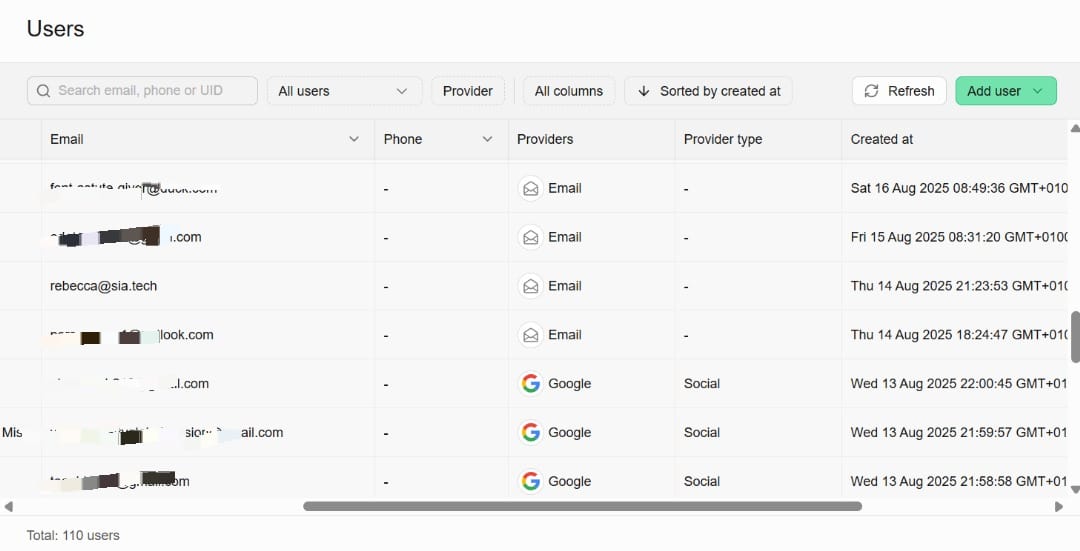
Below are some snapshots of some current analytics:
Users
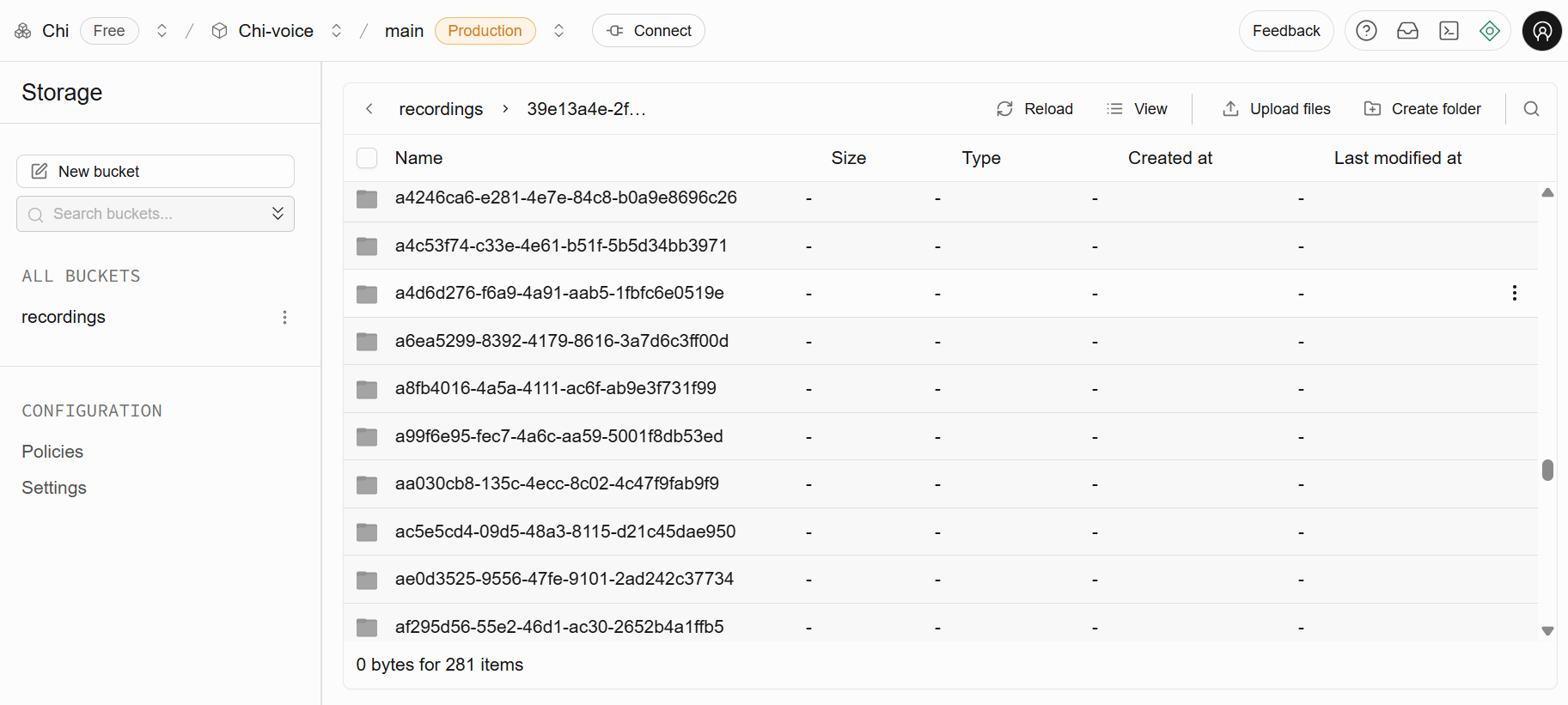
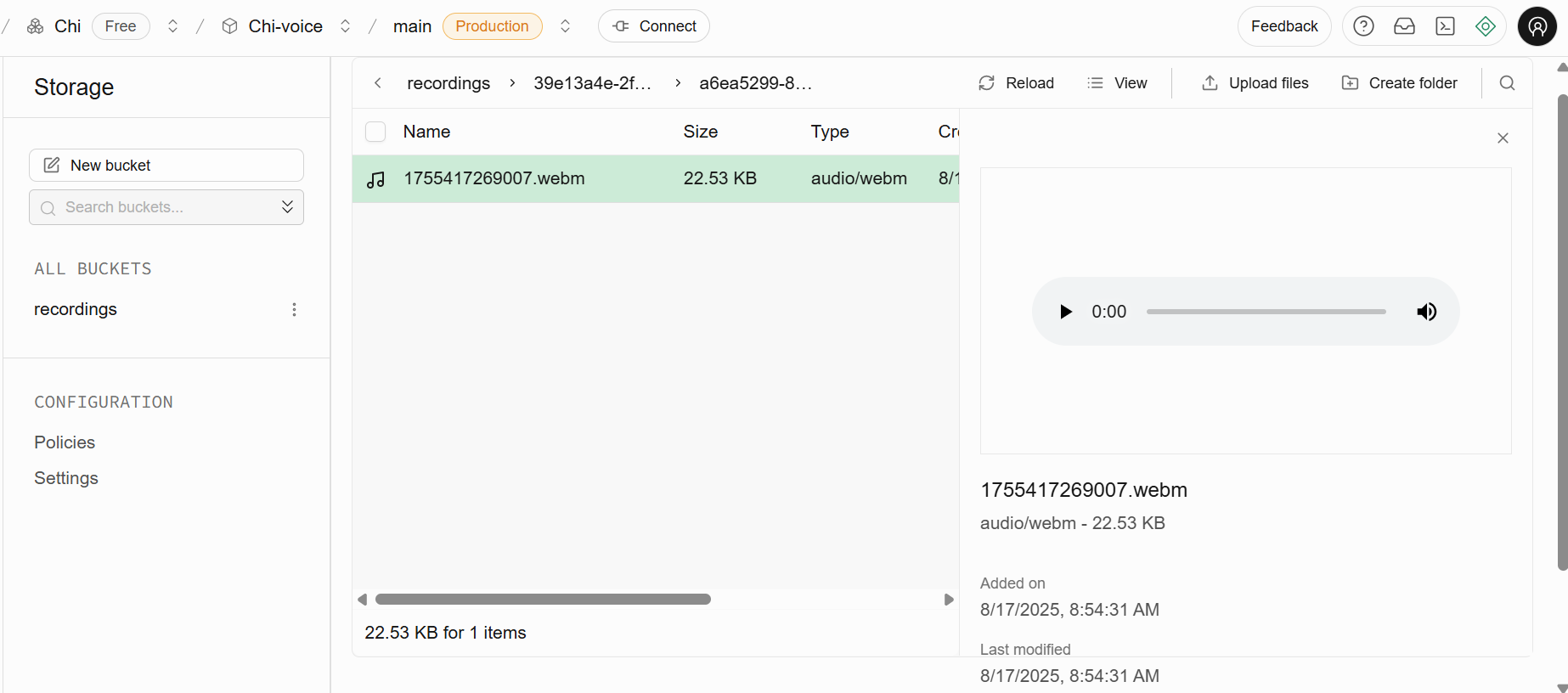
Recordings
Built some AI tools before my final exams and will push all of those to the github as well
Thanks again.