Project Name: Chi, A Community-Powered Platform for Multilingual Audio Data Collection
Name of the organization or individual submitting the proposal: Princess Innocent
Describe your project
Overview
Chi is a lightweight, privacy-conscious platform designed to collect, organize, and store audio recordings of indigenous languages. The platform enables native speakers to record translations of English words, phrases, and sentences using their own voices, forming a foundational dataset for its future AI translation model.
The global south is home to over 5000 spoken languages, yet most speech AI systems ignore or underrepresent them — due to a lack of accessible, labeled, and inclusive audio datasets. Without data, these languages risk digital extinction.
Endangered languages are currently dying at an accelerated rate because of globalization, mass migration, cultural replacement and linguicide etc. Approximately 454 known languages have become extinct in recent times, with over 3000 (43% of total) spoken languages considered endangered.
Existing efforts (like Mozilla’s Common Voice) barely scratch the surface of Asian and African language diversity and often rely on written text, which excludes non-literate speakers.
Whilst providing users with the list of all spoken lamguages, Chi solves this by:
- Empowering native speakers to record spoken translations of AI generated prompts in their own languages.
- Storing that data securely and decentralized, giving researchers, developers, and communities access to ethically sourced language data.
Chi web currently has:
- 100+ users contributing
- 400+ recordings
- Over 90 languages from 3 continents recorded and counting.
These details are auto updated and can be viewed at the bottom of the home-screen. Link to proof of concept below
Who Benefits From Your Project?
- Linguistics and Researchers
- Accessibility, Representation And Preservation of indigenous languages
- AI And NLP Developers
- Educational Institutions
Open Access To Library
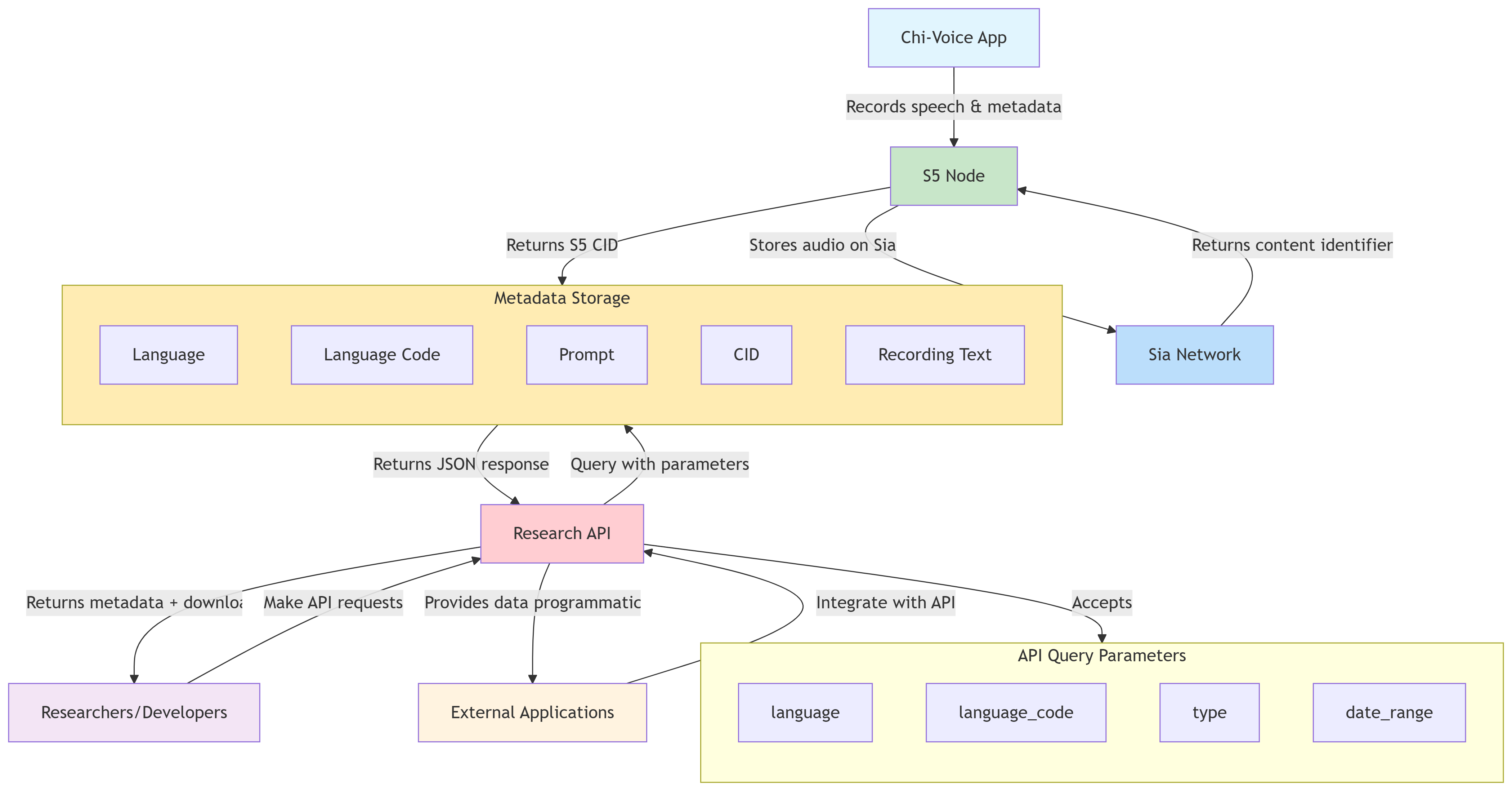
Our recordings library will be made accessible and will support easier integration into ML pipelines for developers as we intend to do same.
we would maintain a database to handle all metadata organization.
Each record will store:
-
Language
-
Language code (glottolog)
-
Prompt (the word/phrase/sentence they were asked to record)
-
CID (pointer to the recording)
-
Recording_text (The transcribed word/phrase/sentence in the target language (optional, if available). Indexed for fast queries.
Develop a simple REST API:
Exposes data directly via REST endpoints.
Researchers/devs make HTTP requests to the API.
query parameters:
language (e.g, “Babanki”)
language_code (e.g, “baba1266”)
type (word /phrase/sentence)
date_range (for collection period)
Returns JSON objects with metadata + CID
-
Researchers and devs query exactly what they need (e.g., one to ten in dhanki, all efifa phrases, all Marathi sentences) fetch metadata, and resolve audio files via S5 CID
-
Directly fetch metadata + download links (via CID) without browsing a UI.
-
Always up-to-date, since API pulls from live database.
Fremium Model
This API will allow developers and researchers to query and retrieve labelled audio data stored on Sia (via S5).
The API will read from Chi-Voice’s metadata database, generate signed URLs/CIDs from the S5 node, and return JSON responses containing both metadata (language, prompt, glottolog code, etc.) and secure links to the audio stored on Sia.
We will adopt a freemium model:
-
Free Tier:
All registered users receive an API key with a generous free quota (for instance 1,000 requests per month). This ensures students, independent researchers and small projects can explore the dataset at no cost. -
Usage Tracking:
Every API request includes the user’s API key. Our middleware tracks usage in real time, comparing each request against the user’s quota. This approach guarantees predictable server load and equitable access. -
Paid Tiers:
When a user exceeds the free quota, they are prompted to upgrade to a paid plan. Paid tiers unlock higher call volumes (e.g 10,000+ calls/month) for institutional users, commercial projects and large-scale model training.
The API backend maintains:
a users table (ID, API key, plan, usage counters),
a plans table (quotas and pricing),
and middleware that enforces quotas, blocks overages, and logs usage.
This freemium model allows Chi-Voice to remain openly accessible for grassroots researchers while creating a sustainable revenue stream from high-volume users. It also positions the project for long-term maintenance and growth
Why Sia is the appropriate fit:
- Sia provides a decentralized, cost-efficient archival storage layer with strong incentives for host stability. This aligns with our mission of making voice-data publicly accessible and citable.
- Using Sia + S5 allows us to embed content identifiers (CIDs) into our metadata exporter, enabling reproducible dataset access and auditability (researchers can trace each file to the content hash).
- Sia’s open-contract model supports long-term budgeting of storage at predictable rates (we model this in our cost plan). That enables us to commit funds ahead-of-time for contract renewals, aligning with our freemium API monetization plan.
How Does The Project Serve The Foundation’s Mission Of User-owned Data?
1. Decentralized Preservation of Cultural Knowledge
Indigenous languages are disappearing faster than they can be documented. By using Sia:
- We store cultural data securely and immutably.
- Consolidating required dataset for model training.
- The project demonstrates how Web3 tools can protect heritage not just finance, and we hope the Foundation sees it’s value and potential.
2. Data Ownership for Indigenous Contributors
Chi is designed so that native speakers contribute voice recordings with full knowledge and consent — and their contributions are stored on Sia’s decentralized network.
This ensures:
- Transparency: Contributors can verify and access the content they help create.
- Autonomy: No corporation, government, or institution can lock or alter the cultural data once it’s on Sia.
3. Model for Future Decentralized Datasets
Chi Voice will serve as a replicable framework for other regions and cultures to follow.
By showing how Sia can power large-scale, ethically sourced voice datasets, we:
- Encourage developers and researchers to use Sia for decentralized data hosting
- Create momentum for a new standard of AI dataset sovereignty
Are you a resident of any jurisdiction on that list? No
Will your payment bank account be located in any jurisdiction on that list? No
Grant Specifics
Amount of money requested and justification with a reasonable breakdown of expenses:
Use of Funds: $35,000 requested
| Item | Amount (USD) |
|---|---|
| Developer fees (full-stack platform development) | $32,000 |
| Open AI (gpt5) API fees (estimated 25 tokens per output $75/m) | $1,000 |
| Storage fees (1year) | $1,000 |
| App platforms fees | $125 |
| Web+Server hosting (1 year) | $375 |
| Logo design | $500 |
What are the goals of this standard grant? Please provide a general timeline for completion.
Our goals are:
- Develop a mobile application for the Chi platform.
- Improve the existing web-app, UI/UX and add interesting features.
- Integrate Sia storage.
- Develop a simple public API for developers access to recordings library
Month 1-2: Mobile App Development (Cross-Platform)
- Define mobile-specific features and UI changes.
- Implement UI design.
Month 2:
- Integrate audio input/output for mobile.
- Implement push notifications.
- Add offline mode & language caching.
- Connect with back-end.
Month 3:
Sia-Storage Integration
- Integrate Sia storage
- Develop a simple REST API to act as a public-facing portal for library access
- Move and store existing and future Audio files via S5
Month 4: Test and Fixes
- Optimize for performance and battery use
- Internal QA and bug fixes.
- Beta release to test group.
Month 5: App Release
- App Store & Play Store listing setup.
- Official app launch
Potential risks that will affect the outcome of the project:
-
Low Participation in Rare Languages
Some indigenous languages may have few active speakers, limiting dataset diversity. -
Poor Audio Quality
Background noise or unclear recordings may affect usability of submissions. -
Incorrect Language Labeling
Users may misidentify dialects, leading to inaccurate metadata. -
Internet Access Constraints
Contributors in rural areas may face challenges uploading recordings due to weak connectivity. -
Legal Risk
Data Privacy & Consent
Mitigations
- Partner with local communities, NGOs and language groups to drive targeted outreach.
- Provide in-app audio quality checks and guides for optimal recording.
- Use verification by native speakers and cross-check with multiple submissions of same language.
- Enable offline recording with later upload when connectivity improves.
- Obtain explicit user consent, provide clear terms of use and comply with data protection laws.
Development Information
Will all of your project’s code be open-source? Yes
Leave a link where code will be accessible for review:
https://github.com/Chi-voice/voice-seed-vault
Do you agree to submit monthly progress reports?
Yes — we will submit reports on our progress here on the forum.
Have you developed a proof of concept for this idea already?
Yes, it can be accessed at https://chivr.tech/
Contact info
Email: [email protected]