Progress Report for the PBS Cloud Backup module - Jan 2024
What progress was made on your grant this month?
Phase 4. Study the PBS tape feature:
• Acknowledging the significant role of layers in distinguishing and differentiating between various reading sources.
• Required understanding how different layers contribute to the processing and interpretation of information from different inputs. So that the same could be applied in cloud backup.
Phase 5. Build the cloud backup module:
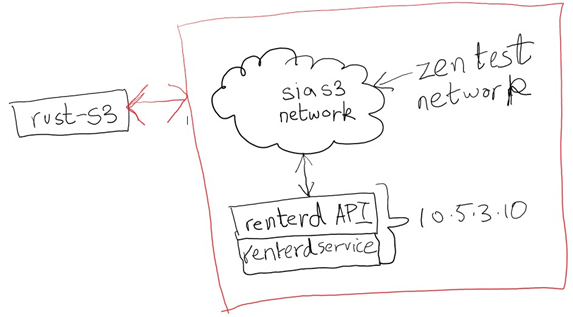
• Setup renterd configuration
• Accessed the renterd portal
• Worked on the renterd API with client
• Understanding the underlying protocols, encryption methods, and data transfer processes utilized by Proxmox VE to facilitate efficient and secure backup operations
• Started making code changes for the cloud backup module.
• Created a cloud backup api stub endpoint
• Assessing Proxmox for supporting multiple cloud providers via plugins
Accomplishments for the Month:
• Moved towards building the cloud backup feature, started the initial phase of the development
The Following tasks were closed this month in openproject (project management tool) :
• Dive deep into tape_read, read, and block_reader traits
• api.rs
• backup.rs
• restore.rs
• Understand how the implementation is reading chunks
• Understand the backup flow of tape feature
• Grasp the abstraction layer functionality
• Acknowledge the layer’s role in differentiating between reading sources
• Study the write feature for trait implementation
• Study the restore feature for trait implementation
• Study the backup schedule and triggering functionality
• Study the feature for understanding incremental file saving approach
• Study the proxmox backup protocol
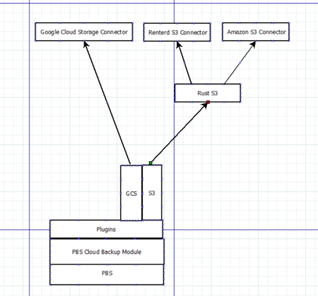
• Develop a Plugin-Enabled Module for Cloud Storage
• Architectural Consideration
• Implement the Strategy Pattern
• Understand its role in algorithm encapsulation and interchangeability
• Implement Restore Functionality
• Enable file-level and snapshot-level restores
• Allow selective restores based on timestamps, file types, etc
• Implement Backup Functionality
• Support full and incremental backups
• Write incremental, fully deduplicated backup files
• Manage versioning and ensure data integrity during backups
Links to repos worked on this month:
GitHub - AZComputerSolutions/PBSCloudBackupModule
What will you be working on this month?
During this month the backup module’s development would be continued, which will include:
Implementation of Backup functionality
• Adding of the cloud backup module
• Implement the cloud backup api under the path (/api2/json/cloud/backup)
• Add the following functionality in relation to the cloud backup module:
1. Modify the PoolWriter, CatalogSet, NewChunksIterator for the cloud module.
2. Implement the releveant functionality and removing existing tape functionality, like MediaPool, used_tapes, etc.
• Following structs/traits need to be implemented in relation to the cloud backup functionality in api2/cloud/backup.rs:
1. TapeBackupJobStatus → CloudBackupJobStatus
2. TapeBackupJobConfig → CloudBackupJobConfig
3. TapeBackupJobSetup → CloudBackupJobSetup
4. TapeBackupJobStatus → CloudBackupJobStatus
5. TapeBackupJobSummary → CloudBackupJobSummary
6. use::crate::tape → change to relevant cloud trait and implement the functionality
7. TAPE_BACKUP_JOB_ROUTER → CLOUD_BACKUP_JOB_ROUTER
8. tape-backup-job → cloud-backup-job
9. do_tape_backup_job → do_cloud_bakcup_job
10. backup_job.setup → implement relevant cloud functionality, to accept cloud jobs
11. let drive_lock = lock_tape_device(&drive_config, &setup.drive)?; → tape locking and device locking functionality needs to be removed
12. let _ = set_tape_device_state(&setup.drive, “”); → tape status needs to be removed
13. TAPE_STATUS_DIR → needs to be removed
14. pool_writer.set_media_status_full(&uuid)?; → This would be done along with the CatalogSet and NewChunksIterator as mentioned above
15. bail!(“Tape backup finished with some errors. Please check the task log.”); → Update the notifications according to the notifications from S3 network
16. summary.used_tapes = match pool_writer.get_used_media_labels() → after the classes, mentioned above are modified, this would be implemented according to the cloud
Currently the development is being done in an isolated repository. As mentioned in the risks initially, there are chances that this S3 cloud backup feature does not get accepted into the code base of proxmox so in the short term we have elected to isolate the code until it does get accepted.
Development of the proxmox backup feature has started, although slow, the cloud api endpoint stub has been implemented using the same code structure as the tape backup feature.